EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language Models
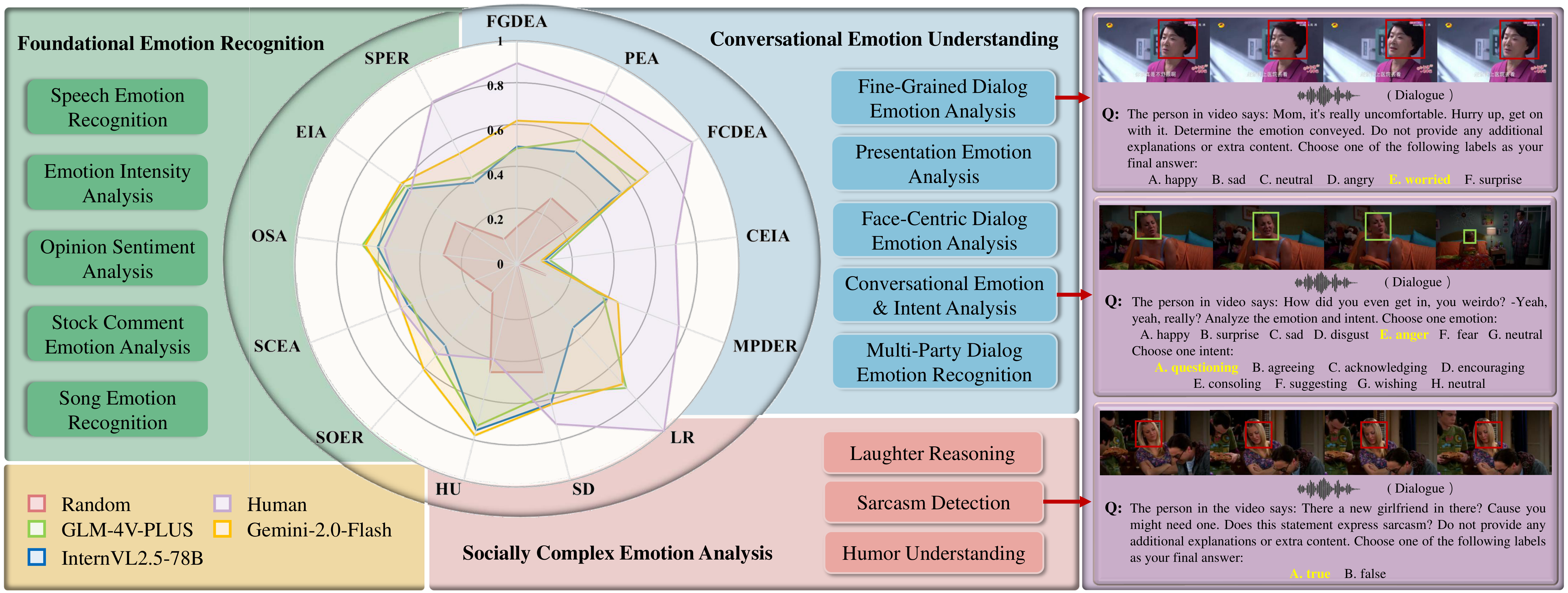
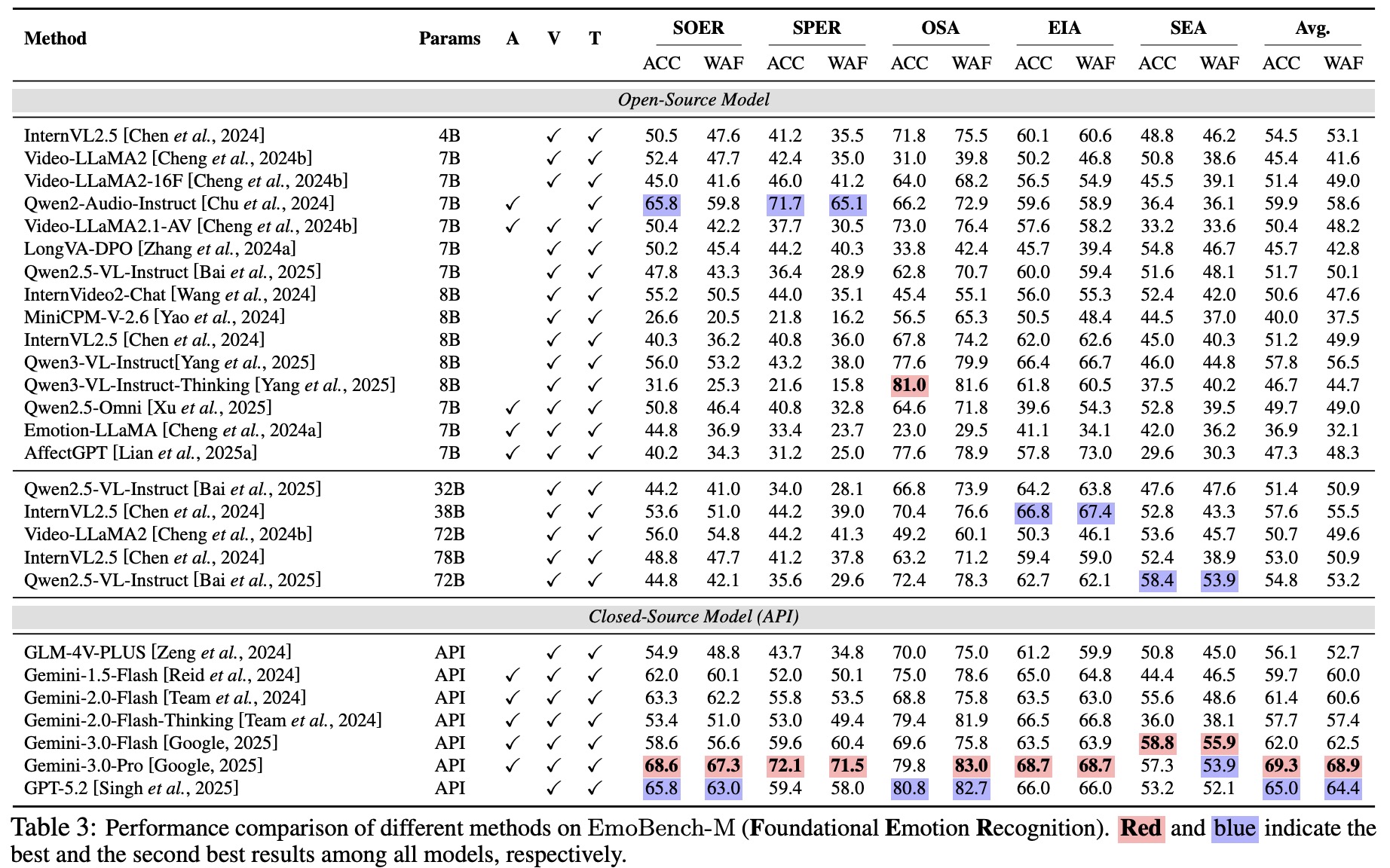
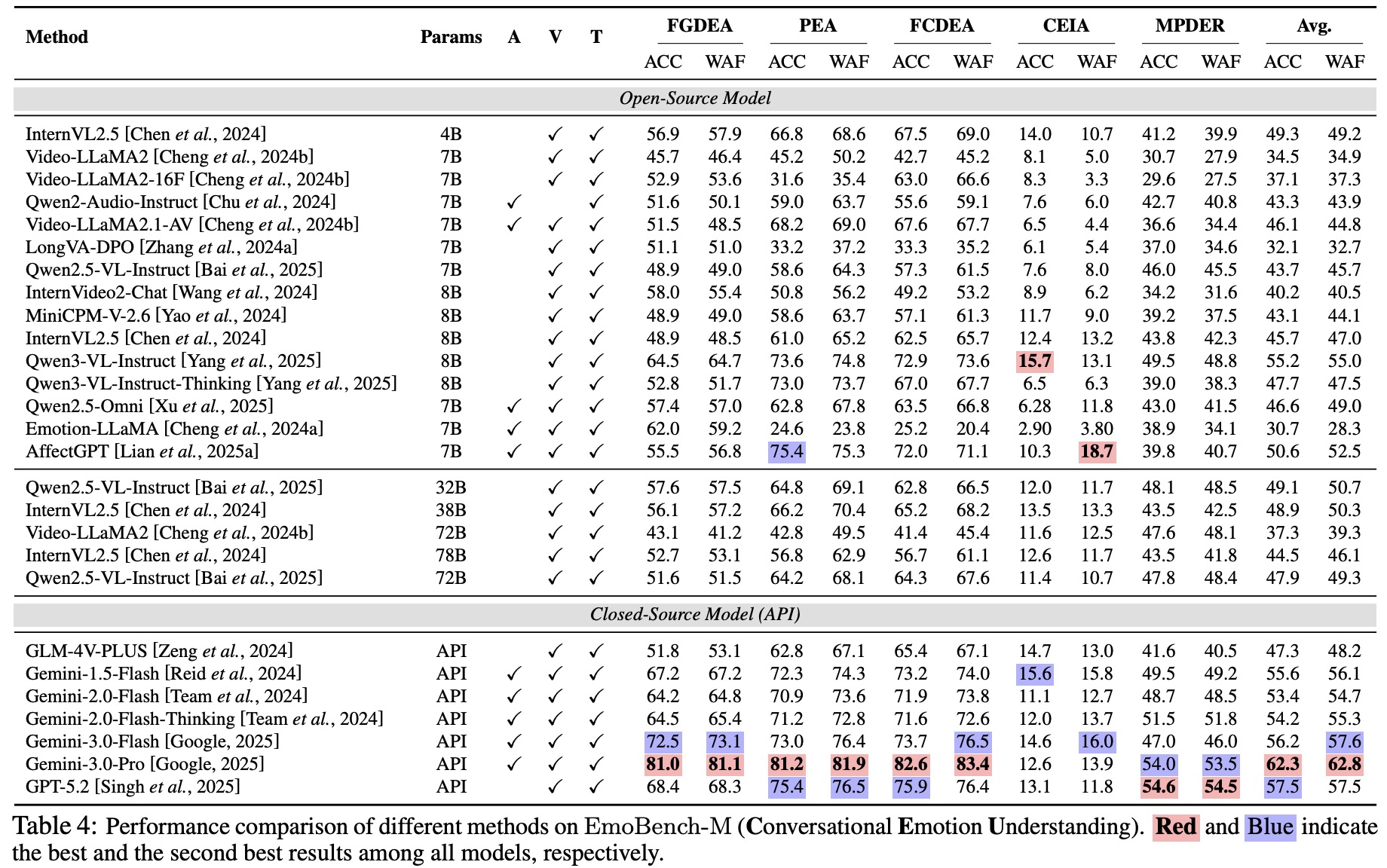
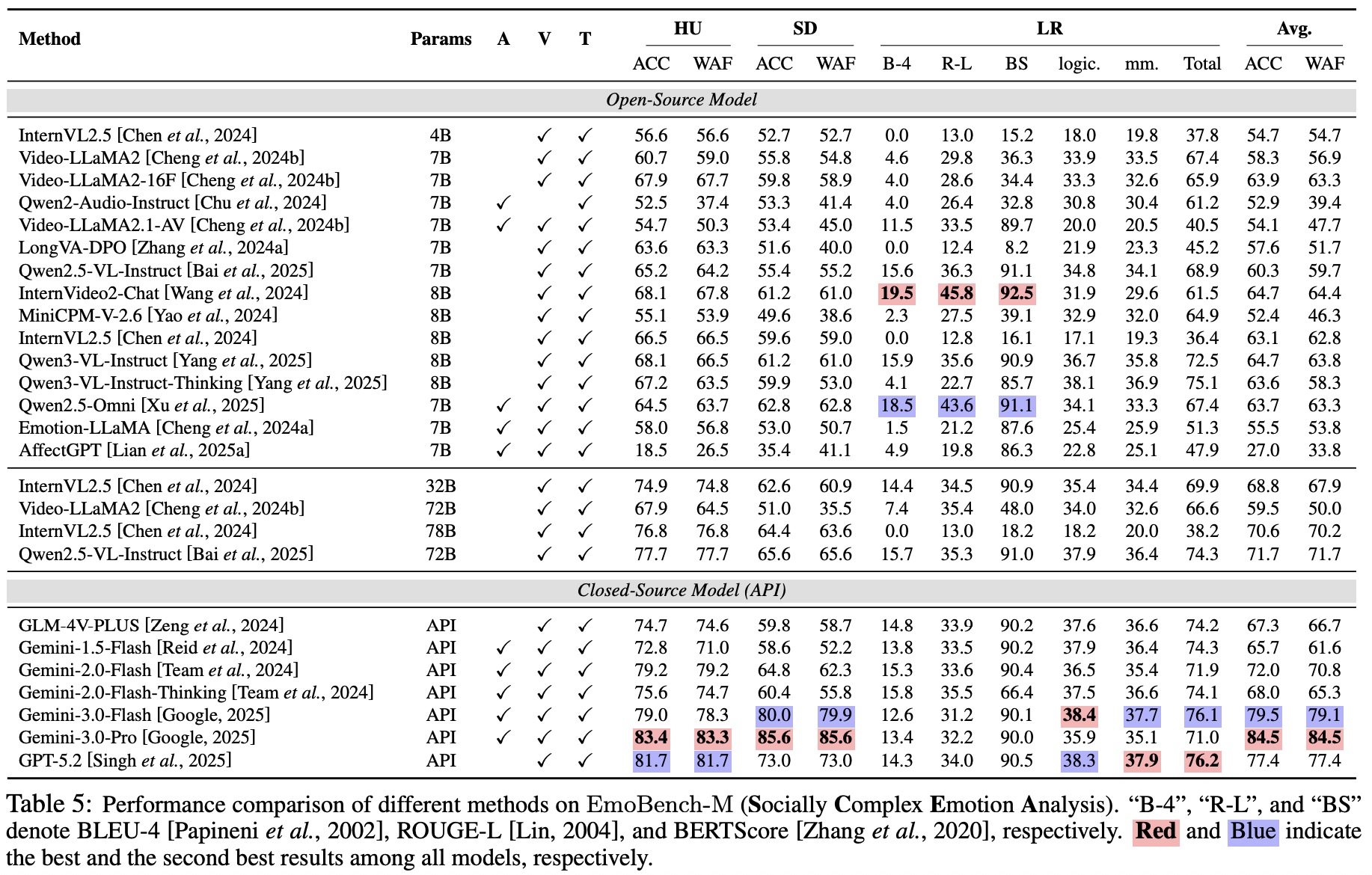
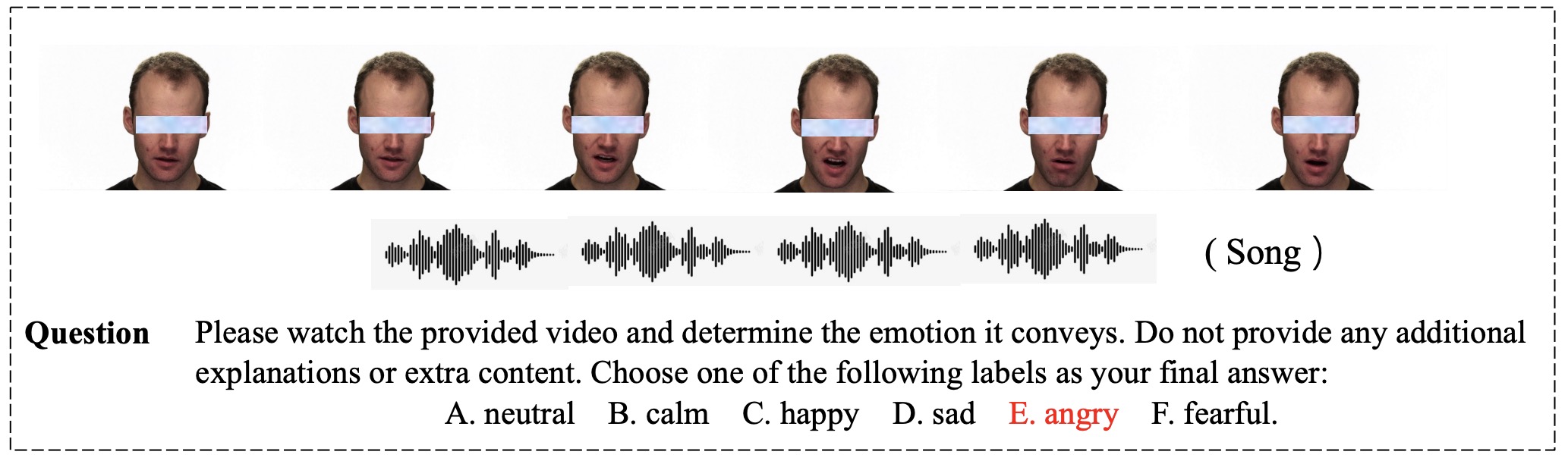
EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language ModelsWith the integration of Multimodal large language models (MLLMs) into robotic systems and various AI applications, embedding emotional intelligence (EI) capabilities into these models is essential for enabling robots to effectively address human emotional needs and interact seamlessly in real-world scenarios. While benchmarks for evaluating EI in MLLMs have been developed, they primarily focus on static, text-based, or text-image tasks, overlooking the multimodal complexities of real-world interactions, which often involve video, audio, and dynamic contexts. Based on established psychological theories of EI, we build EmoBench-M, a novel benchmark designed to evaluate the EI capability of MLLMs across 13 valuation scenarios from three key dimensions: foundational emotion recognition, conversational emotion understanding, and socially complex emotion analysis. Evaluations of open-source and closedsource MLLMs on EmoBench-M reveal a significant performance gap between MLLMs and humans across many scenarios. The findings underscore the need for further advancements in EI capabilities of MLLMs. All benchmark resources, including code and datasets, will be publicly released.












@article{hu2025emobench,
title={EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language Models},
author={Hu, He and Zhou, Yucheng and You, Lianzhong and Xu, Hongbo and Wang, Qianning and Lian, Zheng and Yu, Fei Richard and Ma, Fei and Cui, Laizhong},
journal={arXiv preprint arXiv:2502.04424},
year={2025}
}